AI 时代为什么元认知最重要
Hassabis 跑去读神经科学博士,张雪初中辍学造出世界冠军赛车。两个反方向的人物,指向同一件事——决定能力上限的不是学历和知识,是元认知。
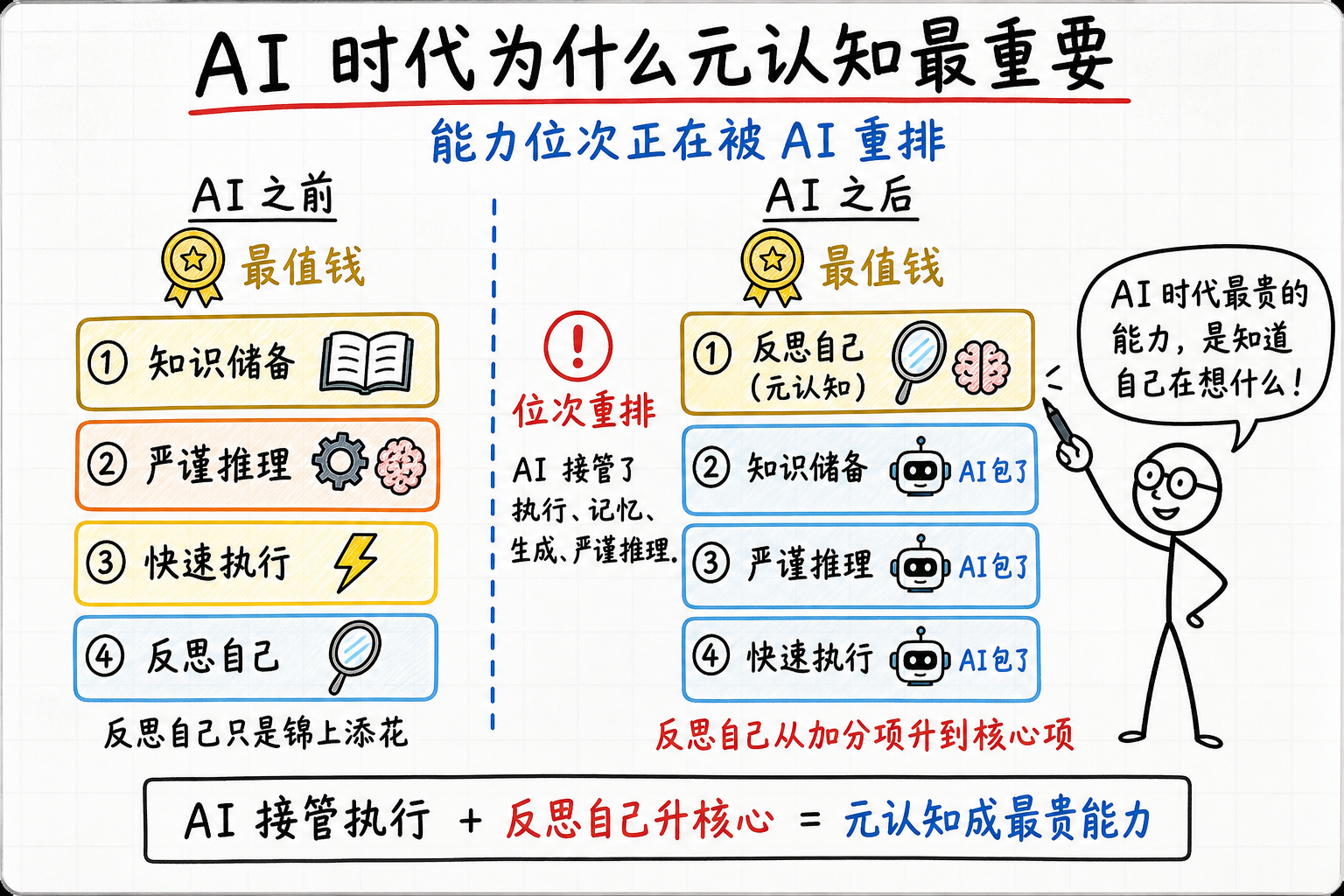
引子:一个初中辍学,一个剑桥博士,赢在同一种能力上
2026年3月,葡萄牙波尔蒂芒。世界超级摩托车锦标赛上,一台中国造的赛车连下两个回合冠军,第一回合领先第二名3秒多。在这个项目里,这是非常大的差距。造车的人叫张雪:初中辍学,从修理铺洗零件的学徒干起,最高学历初中。
往前推些年,另一个人走的是完全相反的方向。剑桥计算机本科,那个年代顶尖的游戏AI程序员,本可以顺这条路一直做下去——他却停下来,去读了六七年认知神经科学博士,钻研海马体和记忆。他叫Demis Hassabis,后来创办DeepMind,做出AlphaGo、AlphaFold,还拿了2024年的诺贝尔化学奖。
一个一头扎进实践、把手艺磨到世界级;一个从顺风顺水的实践里抽身,去啃最底层的理论。一个身上没有半点学历光环,一个光环堆满。路子完全相反,做成的却都是各自领域里别人做不成的事。
他们共同具备什么特质?
Hassabis那六七年绕路,当时没人懂:一个一线游戏AI程序员跑去研究海马体,图什么?后来才清楚——他要的从来都是智能本身,不是更好的AI程序;而当时能反复研究智能的真实样本,只有大脑。他判断单靠游戏AI那套工程经验根本到不了想去的地方,所以宁可绕开。
张雪这边,一个修车铺出身、没名校学历也不在欧洲赛车工程体系里的人,发动机、车架、调校、供应链每一项都是真刀真枪,他怎么一步步逼到世界级?光靠埋头苦干解释不通。那只会让你在原地把同一件事重复一万遍。
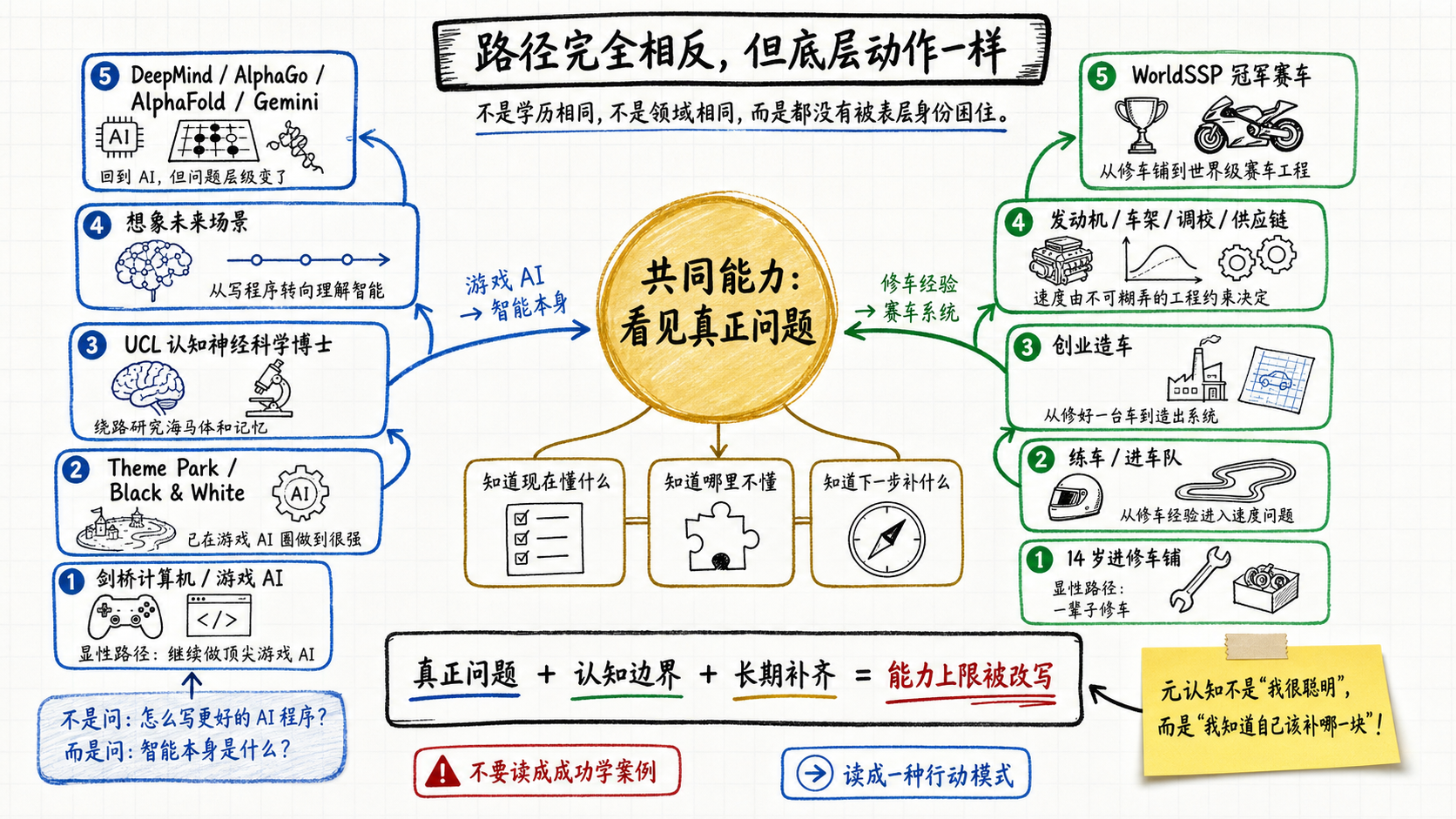
他们做的是同一个动作:很长的时间里,对我现在站在哪、离真正要解决的问题还差多少,始终保持清醒。Hassabis判断游戏AI走不到AGI,于是转身;张雪清楚自己每一项还差在哪,于是一件件补上来。
他们靠的,是把平时向外打量世界的目光反过来对准自己。这就是元认知。
AI替代人这件事,我不是旁观者——我自己就在做AI Coding工程能力建设,某种意义上正是在加速它。程序员手里的活正一块块被接管,尤其那些能被明确验证的、独立的任务,AI已经做得比我又快又好。所以"人还剩下什么不可替代",是我时常在思考的问题。
AI时代最隐蔽的陷阱,是它能把你没想清楚的问题,包装成一份看起来已经想清楚的答案——结构、语气、细节样样齐全,你以为问题推进了,其实最该自己想的那一步被跳过了。
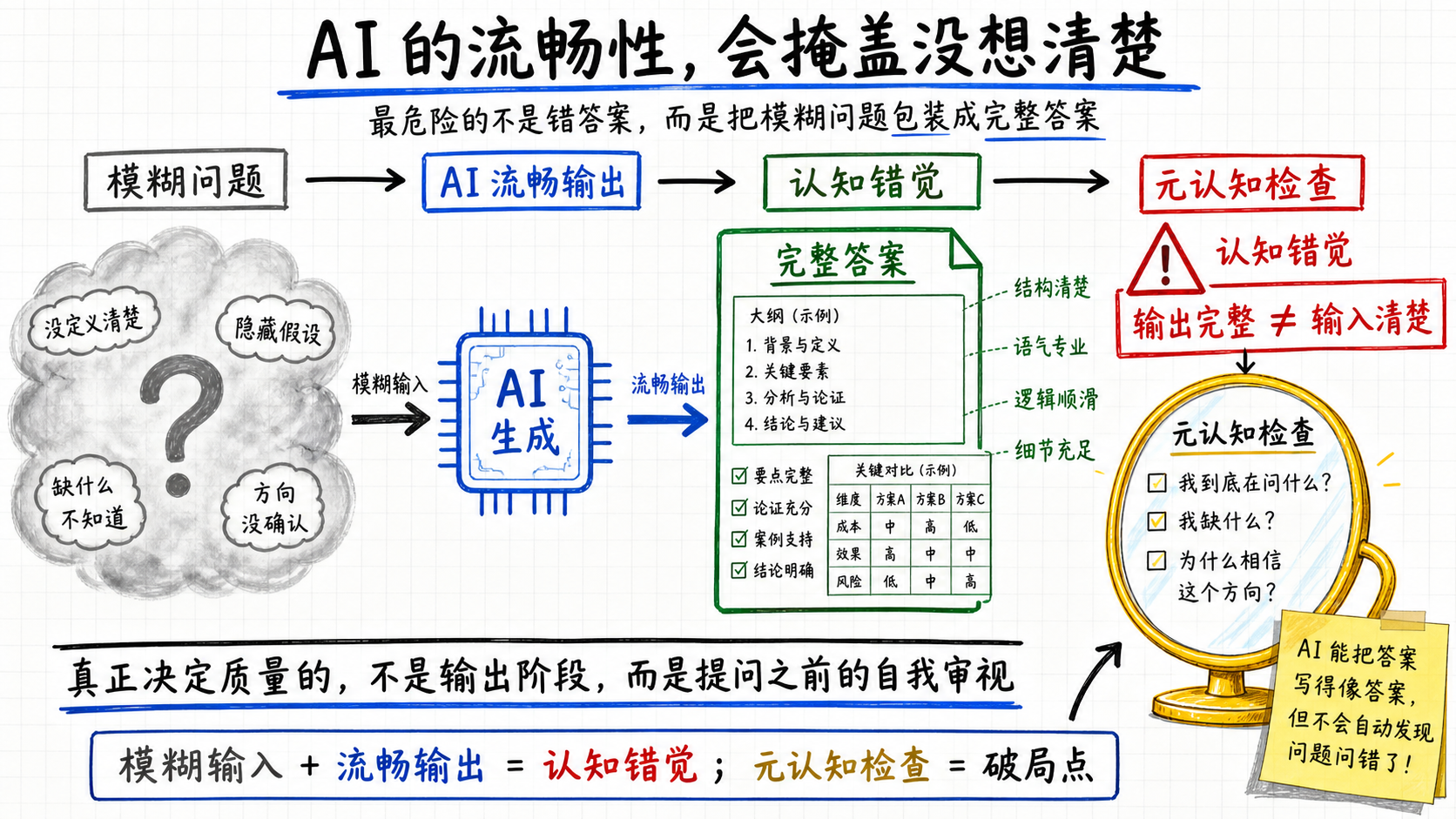
越往这条路走,先看清自己到底想没想清楚,就越值钱。Hassabis和张雪那种能力,正是在这里从加分项被顶成了核心项。
一、先理解大脑是怎么工作的
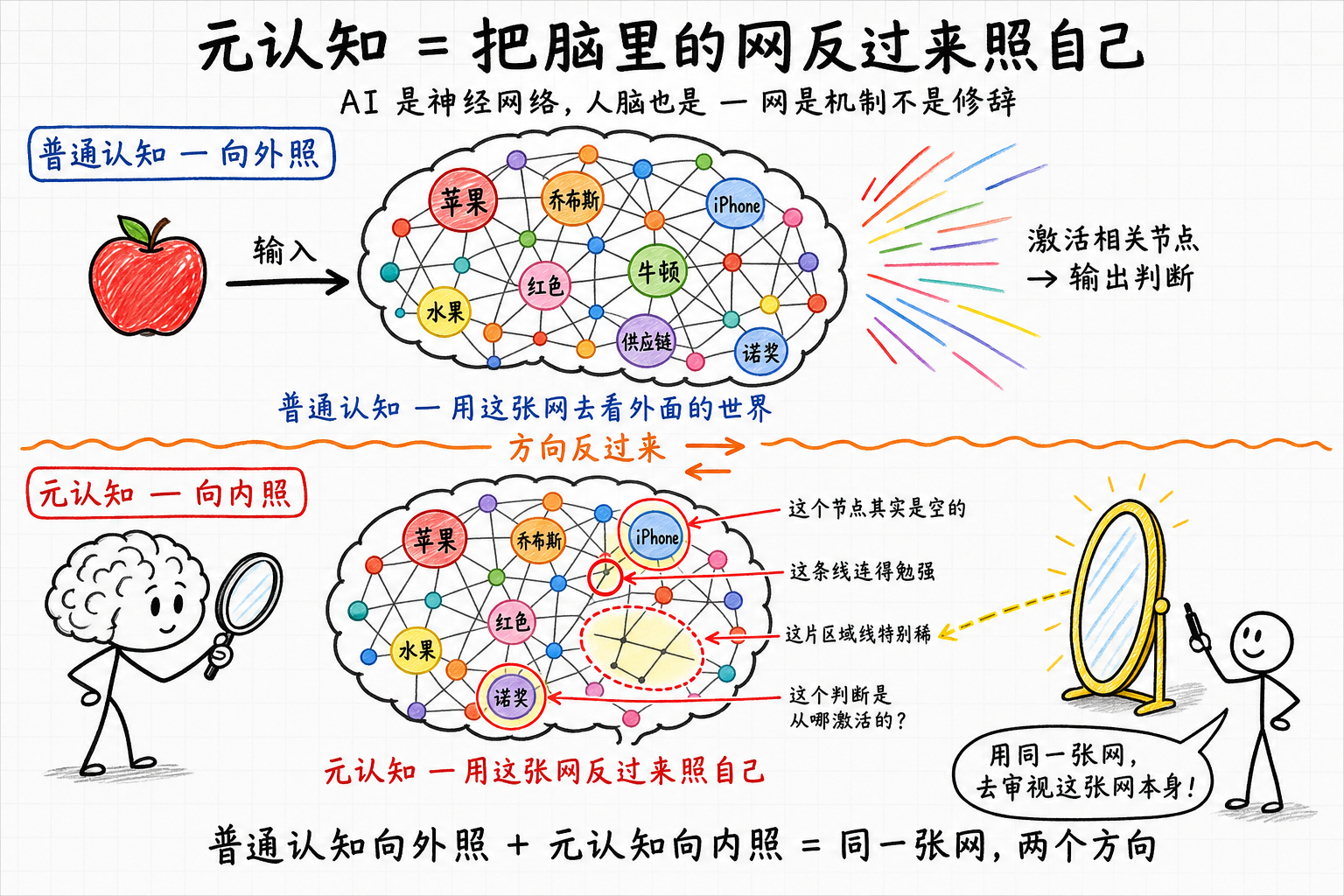
先理解认知的定义。心理学里常把知识分成几类:事实性知识(什么是什么)、概念性知识(概念之间的关系)、过程性知识(怎么做)、元认知(对自己认知的认知)。这几类不是孤立存放的,更像一张网。
网在这里不只是修辞。AI是神经网络,人脑也依赖神经元连接和激活模式工作;脑里的概念关联,跟工程上的知识图谱、latent space、关联记忆并不完全等同,但都在描述同一类问题:信息不是孤立存在的,某种意义上,信息的单节点脱离了关系就失去意义了。轻实体,而重链接,链接本身的重要性甚至要远远高于实体。
举个看似平常的例子:苹果。
听到这两个字,每个人脑里被点亮的东西不一样。学物理的人想到牛顿和万有引力;程序员想到iPhone、想到iOS、想到乔布斯;做电商的人想到客单价、想到SKU、想到生鲜冷链;果农想到富士、嘎啦、红将军这几个品种的成熟期和收购价;做中医的人想到肺经、想到秋燥润肺。同一个词,激活的是完全不同的网络。
这件事说明两件事:
第一,知识是按"与之相关联的周边信息"存的,不是按孤立节点存的。 同样听一节课,两个人记下来的东西可能完全不同。差别不在谁更努力,在于两人脑里的挂点本来就不一样。新知识进来,得先找到挂点才能存住,找不到就掉了。这是为什么对一个完全陌生的领域,听再多课收效都差:脑子里没有挂点,新内容像砸到光滑墙面上,弹回来。
第二,一个人脑里这张网长什么样,是他这辈子见过什么、做过什么、想过什么决定的。 两个看起来同样聪明的人,听到同一句话,激活的概念可能完全不重合,所以他们的判断会完全不同。这无关观点,是底层网络结构的差异。一个判断你觉得不可理喻、对方觉得理所当然,多半也无关对错,只是你们脑里那张网在同一个词上挂的东西不一样。
回到Hassabis那个故事——他会跑去读神经科学博士,是因为他脑里的网早就把游戏AI和智能本身这两个节点连上了,所以他能看出游戏AI这条路再走下去也到不了AGI。一个普通游戏AI程序员脑里的网,游戏AI挂在性能优化、玩法体验这些节点旁边,根本不会跟智能的底层结构连起来。同样听到我要做更好的AI这句话,两个人激活的网络完全不同——所以走的路完全不同。
这一点在脑科学和AI两边都有呼应:无论是神经网络里的attention,还是大脑组织概念的方式,都是在动态寻找元素之间的关系——智能是组织关系,不是堆事实。
所以可以先用一个粗糙但有用的模型理解:人脑和AI模型都在把世界拆成节点,再在节点之间织线。一个人聪不聪明,不只取决于他存了多少节点,也取决于他在节点之间织了多少线、织得多准。
现在可以把元认知放回这个框架里:
普通认知,是用这张网去看外面的世界。看一个新事物,激活相关节点,找到关系,做出判断。套用现有LLM的术语,普通认知是在做inference。
元认知,像是训练时在做的反向传播,是把这张网反过来照自己:
- 我刚才那个判断,是从哪几个节点激活出来的?
- 那几个节点之间的线,是真的连得起来,还是我一厢情愿连上去的?
- 我有没有一个节点其实是空的,但我以为它装着东西?
- 我有没有一片区域线特别稀,所以我在那里的判断其实不可靠?
这就是为什么元认知难。你要用同一张网,去审视这张网本身。这是一个递归动作,跟用自己的眼睛看自己一样别扭。多数人一辈子都没意识到自己可以这么做,更别说常常做。
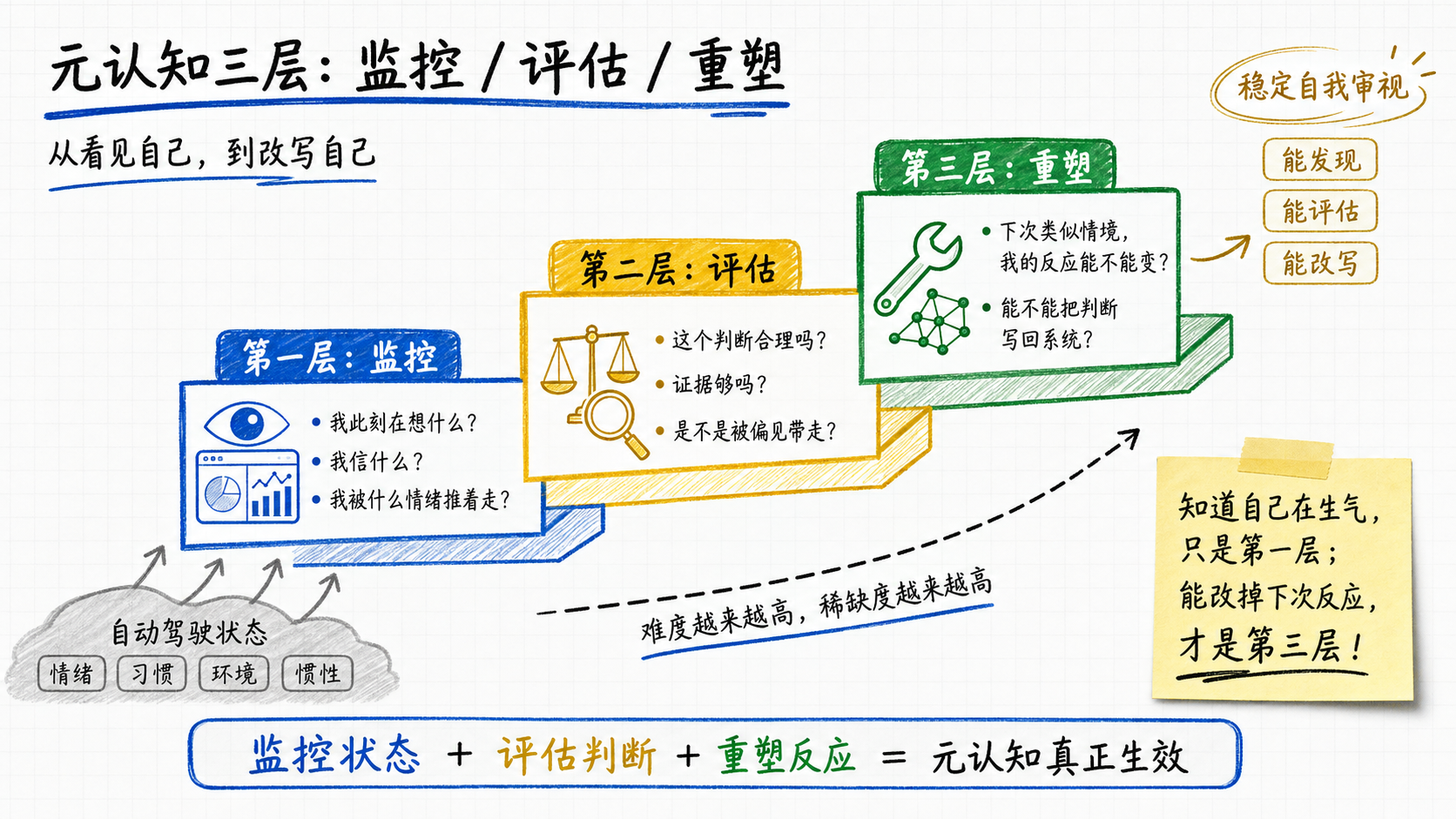
二、元认知本身:监控、评估、重塑
元认知是三层叠在一起的。
第一层:监控。 你能不能意识到自己此刻在想什么、信什么、在用什么状态做判断?
最简单的测试:你在生气的时候,能不能在生气的当下意识到"我正在生气"?你在嫉妒别人的时候,能不能察觉到"我正在嫉妒"?你跟人争执时,能不能看到"我现在不是在追求对的答案,是在追求赢"?
能,就有基本的元认知。这一层听起来简单,但能稳定做到的并不多。情绪一上来,多数人根本意识不到自己正在被推。
第二层:评估。 监控到了之后,能不能判断"这种状态合理不合理"?
我现在很有信心这个方案能成,是因为它真的可行,还是因为这是我自己提的方案?我对那个人评价很低,是因为他真的差,还是因为他三个月前在我朋友面前驳过我?我现在认定X是对的,是因为我想清楚了,还是因为团队里地位高的人这么认为?
这一层比第一层难得多。因为评估的对象是你自己的判断:你必须把"我"和"我的判断"分开看,承认它们不是同一个东西。
第三层:重塑。 评估完之后,能不能主动改写自己对类似情境的反应模式?
知道自己在嫉妒,不一定能让自己下一次不嫉妒。知道自己有"对自己的方案过度乐观"的倾向,不一定能让自己下一次评估方案时保持中立。第三层是把第二层得出的判断真的写回到自己的认知系统里,让下一次的反应不一样。
这一层最稀有。能稳定做到的,已经是道家说的"内观"或者佛家说的"觉照"那个级别。
为什么多数人停在第一层
几个原因互相叠加。
能耗。 监控自己已经费力,评估自己更费力:大脑天然不想做,能省则省。
情感成本。 评估自己的判断意味着可能要承认"我之前是错的"。在生理上承认错误接近承受疼痛,所以人会本能地避开。
环境不奖励。 开会时承认"我刚才的判断有问题",在多数公司文化里不讨好;社交场合主动反思自己更是少见。环境一直在告诉你:把判断说得越坚定越好。AI时代又压上一层:以前你有没有想清楚,外界反馈足够频繁、足够硬,会替你审视;现在AI写的代码大多能跑、文档大多过得去、方案大多看起来合理,反馈变钝了,外界几乎不再替你审视。于是更没有什么力量推你回头照自己。
最致命的一条:你不知道自己不知道。 如果你的盲区在第一层——你压根没意识到自己在做某种判断——后面两层就没机会启动。盲区本身是看不见的,否则它就不叫盲区。
最后这条最难破。出路只有几条:靠环境(混到一群有元认知的人里),靠他人(找一两个敢直接刺你的人定期反馈),靠失败(被重重摔一次之后回头看)。
日常怎么练
把"我"和"我的判断"拆开,不需要修行的高度,日常有几个动作:
- 每做一个判断之前,问一句"我现在凭什么相信这是对的?“是数据、经验、别人说、还是我没认真想?
- 每做完一个判断之后,主动回头想一遍:基于哪几条理由?哪条其实最虚?不用记下来,想这个动作本身就是在练。
- 每隔一段时间问自己"上个月我有没有改变过任何一个观点?“如果完全没有,大概率你停在了第一层。
次数多了,拆开就成了本能,自然能稳定在第二层、偶尔进到第三层。
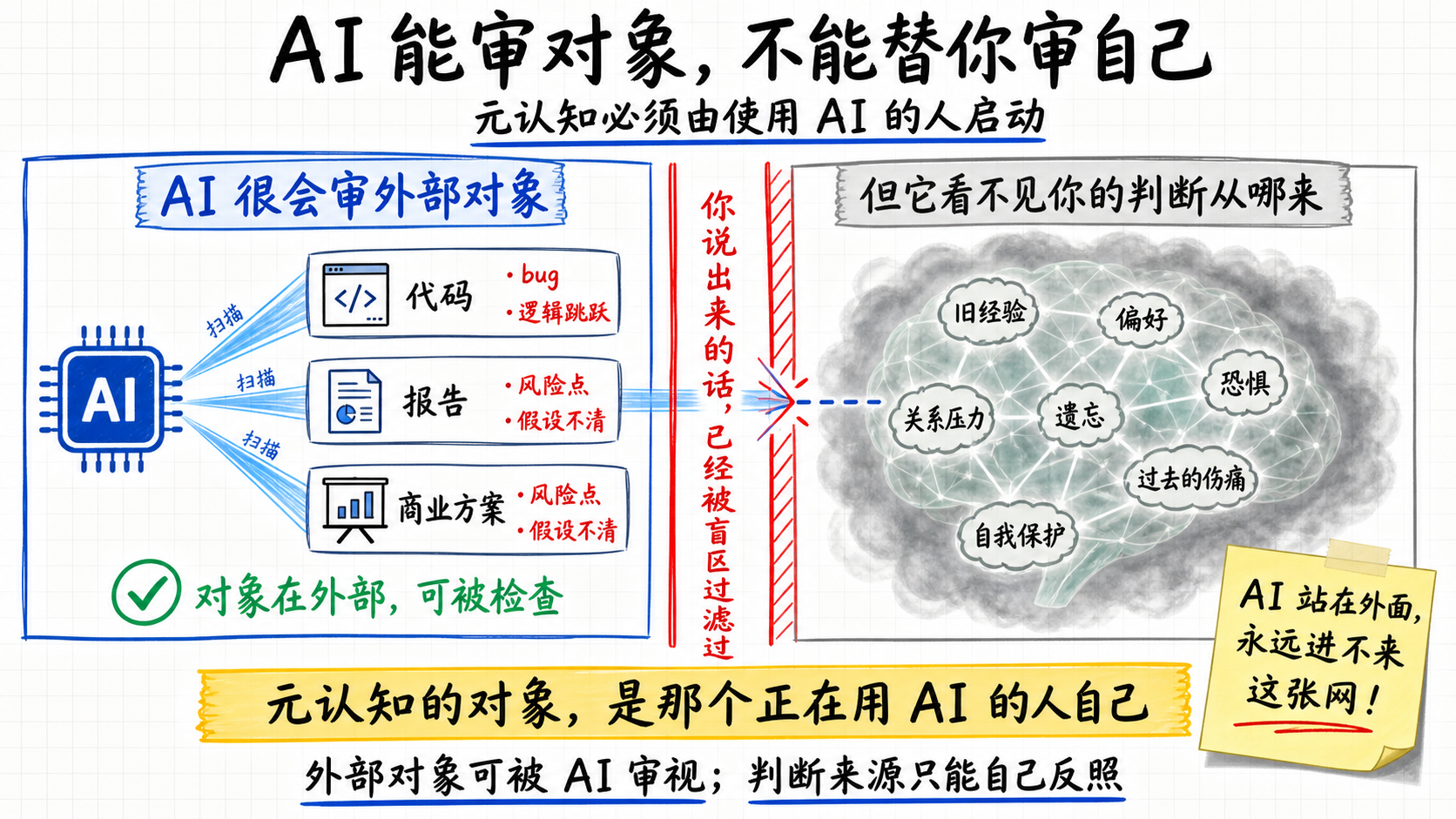
元认知必须自己做
你可以让AI审一段代码、一份报告、一个商业方案——它对外部对象的审视能力一直在变强。
但你没法让AI直接审你的判断本身。它不知道你的判断是从哪片网络里激活的,不知道你基于什么经验、什么偏好、什么遗忘、什么过去的伤痛在做这个判断。它只能根据你说出来的话猜,而你说出来的话本身就被你的盲区过滤过了。
元认知这个动作,结构上只能自己做:它的对象就是那个正在用AI的人。AI站在门外,进不来——但它能把一面镜子递到门口。怎么递,第五章再讲。
三、元认知在学习里:升维
元认知听着抽象,落到具体场景里各有各的形状。先从最日常的学习说起。
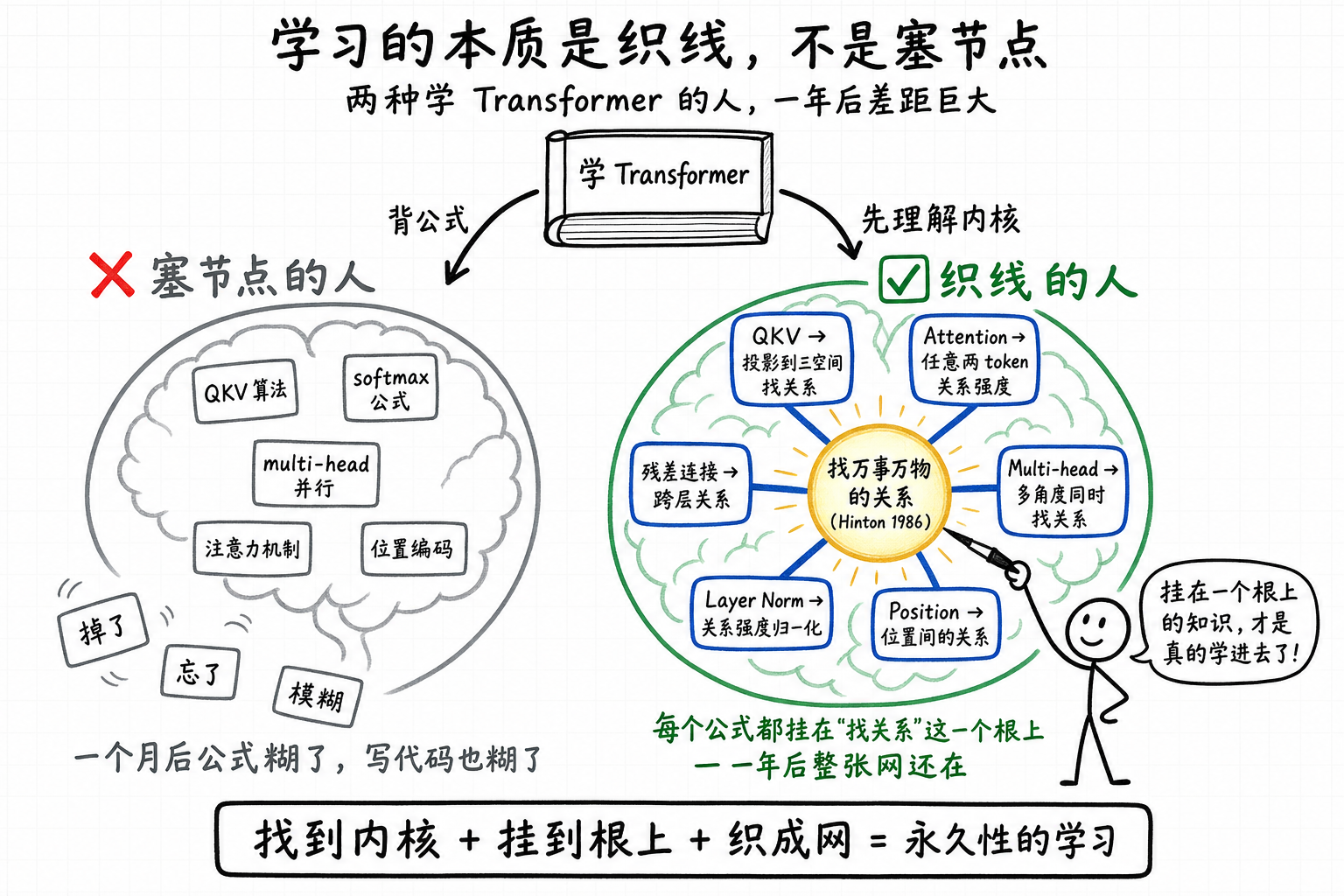
学习里有一个最容易被混淆的分界:记住一个事实,跟把那个事实挂进网络,是两件完全不同的事。表面上都叫"学了”,但前者一年之后留不下什么,后者一年之后整张网都变了。
举个例子。学transformer的人有两种。一种把每个公式背下来:QKV怎么算、attention怎么softmax、multi-head怎么并行。过一个月公式就记不清了,写出来的代码也含糊。
另一种人,学之前先抓住一个原点:神经网络做的很多事情,是在找万事万物之间的关系。然后再看每个具体机制:QKV是把token投影到不同空间去找关系,attention是衡量token之间的关系强度,multi-head是从多个角度同时找关系。每个公式都挂在"找关系"这一个根上。一年后他能用这套框架去解释新出的模型变体,也能反推为什么某些设计走不通。
两种人花的时间差不多,记住的具体内容也差不多。但第一种人脑里是一堆孤立节点,第二种人脑里是一张挂在同一个根上的网。
学习背后有两种推理方式。归纳推理:看几张猫的图片,能认出新的猫。这是从例子归纳到一般。演绎推理:从一个逻辑原点出发往前推,得出新的结论。亚里士多德最早提的"第一性原理"就是这个意思。
AI现在很强的是归纳。喂几个样本,它能识别新样本。很多人的学习也停在归纳的浅层:记几个例子,能套用就行。给AI一个原点,它演绎得比谁都顺;它缺的是替自己挑那个原点。
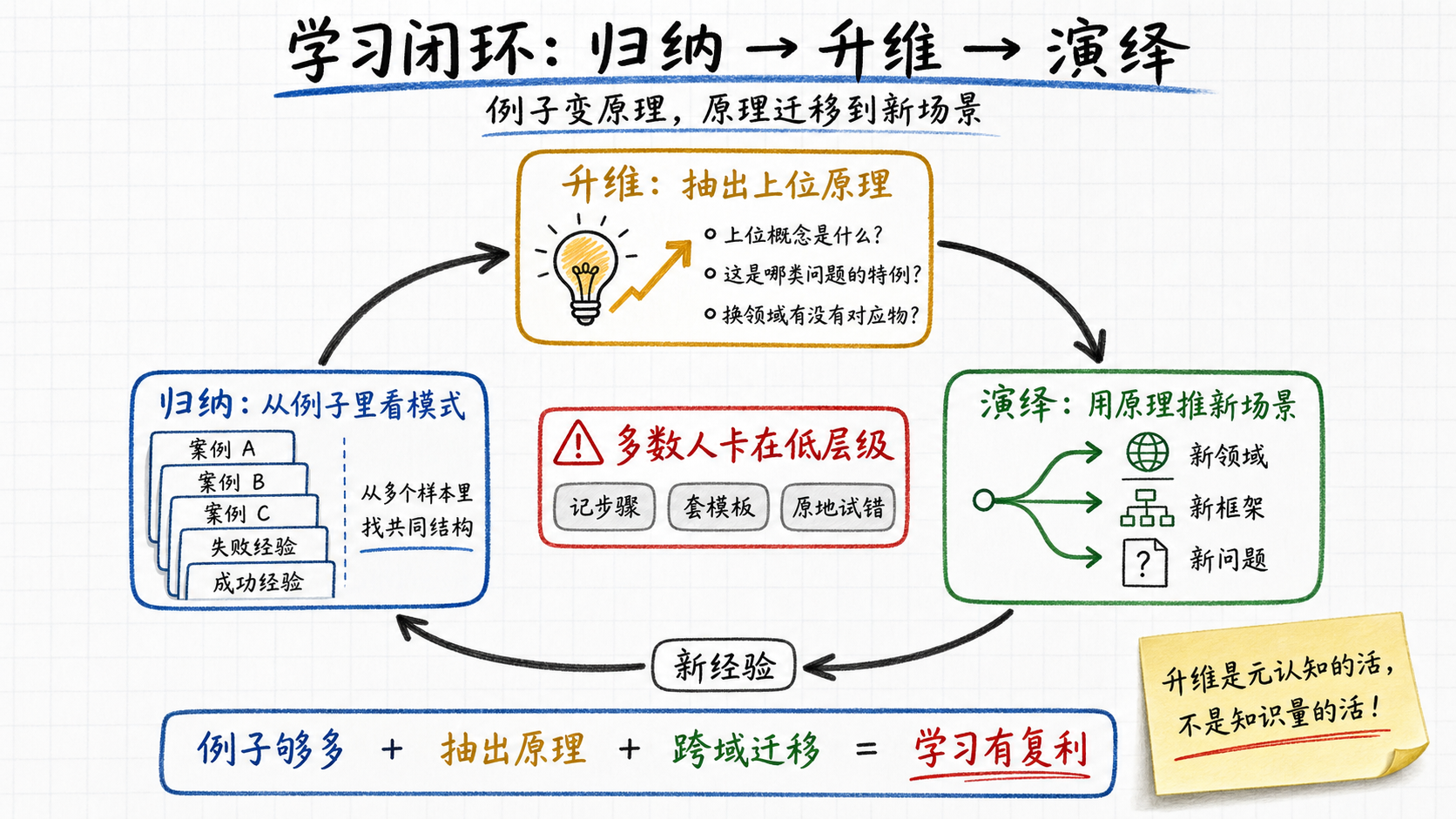
高效的学习,是把归纳和演绎接起来——用归纳积累足够多的例子,从例子里看出原理,然后用原理往下演绎到新场景。这个把例子升到原理的动作,就是升维思考。
升维具体长什么样?
每遇到一个新概念,不直接背它本身,先问三个问题:
- 它的上位概念是什么?这是哪一类问题的一个特例?
- 它跟我已知的哪些概念相似?两者的差异在哪里?
- 如果换一个完全不同的领域,有没有对应物?
举一个最常见的例子。学一个新框架,普通做法是照着tutorial跑示例代码,一周后忘90%。因为你记的是"在X里实现Y要写这几行代码”:孤立节点,没挂在任何更大的结构上。
升维的做法是先问几个问题:这个框架要解决的核心问题是什么?它的设计取舍是什么:为了得到A,它牺牲了哪些B?它跟我用过的另一个Y框架在哪几个维度上不同?
这样学完,新框架同时挂在"某类问题"“设计取舍"“与Y的对比"上。每次想起来都能拉出一片网。一年后那张网还在。
开头那个张雪,也是一路升维上来的。一个只会修车的人,再修一万台也未必造得出冠军车——除非他在某一刻不再只问"这台车哪里异响、怎么修好”,而是开始问"速度、可靠性、成本、规则、车队协同,这几样到底怎么相互掣肘”。前一个问题待在"怎么修"那一层,后一个已经抬到了"一台快车由什么决定"。手艺原地打转,升维的人却把同样的修车经历越垒越高。
升维难就难在,它跟大脑的本能反过来。大脑天然喜欢在低层级转悠:记住具体步骤、套用熟悉模式,能耗最低。每抬升一维,能耗翻倍。所以多数人遇到新问题都在原层级反复试错,从来不主动抬一层去看。
要升维,得先意识到自己现在停留在哪一层——是在记代码还是理解原理,是在套熟悉模式还是追问问题的真实结构。没意识到这一点,你不会觉得自己有什么问题,因为低层级让你觉得"我在做事"“我有进展”。
升维是元认知的活,不是知识的活。
四、元认知在解决问题里:定义问题
学习解决的是往脑里装什么。装好了要拿出来用——工作里多数时间花在找答案上,但拉开人和人差距的,是定义问题。
原因很简单:答案的好坏由问题决定。问题定义偏一度,答案偏一百米。一群人开了二十轮会、加班三个月,做出来一个所有人都觉得"做得很认真"的东西,最后发现整个方向是错的。这种事在每个行业每年都在发生。毛病出在源头:问题从一开始就没定义对,跟执行卖不卖力无关。
定义问题听起来抽象,落到具体场景有几个清晰的层次。
第一层:识别表面问题和真实问题。
最常见的例子:员工说工作不开心想加薪。表面问题是钱。真实问题可能是不被认可、晋升通道堵了、对老板不信任、或者跟同事处不来。加薪解决不了任何一个真实问题。给了,三个月后他还是要走,或者留下来继续耗。
这一层的门槛不高。多数人会,只是没耐心:表面问题摆在那儿,处理掉看起来效率高,往下挖一层要花时间、要承担挖错了的成本。所以就在表面问题上反复打转。
第二层:用不同学科的框架看同一个问题。
同一个问题,用经济学讲、用生物学讲、用心理学讲、用物理学讲——会定义出完全不同的真实问题,对应完全不同的解法。
举个常见的:为什么大公司做不出创新?用经济学讲是激励错位(创新风险高、收益归别人、KPI不鼓励冒险);用生物学讲是组织代谢下降(细胞太多、信号衰减、新陈代谢慢);用物理学讲是熵增(任何系统不主动注入能量就会走向无序)。三种定义各自指向不同的解法:经济学定义对应改激励,生物学定义对应组织拆分,物理学定义对应持续注入新鲜血液。
错的定义带来错的解法。所以"懂得多"在AI时代依然有意义——你手里的框架越多,重新定义问题的可能性就越多。储备本身AI比你强,但储备里有多少能当框架用的东西,是另一回事。
第三层:找逻辑原点。
这是定义问题的最深一层。前两层是"在已有框架里重新切问题",这一层是自己造一个新的框架。
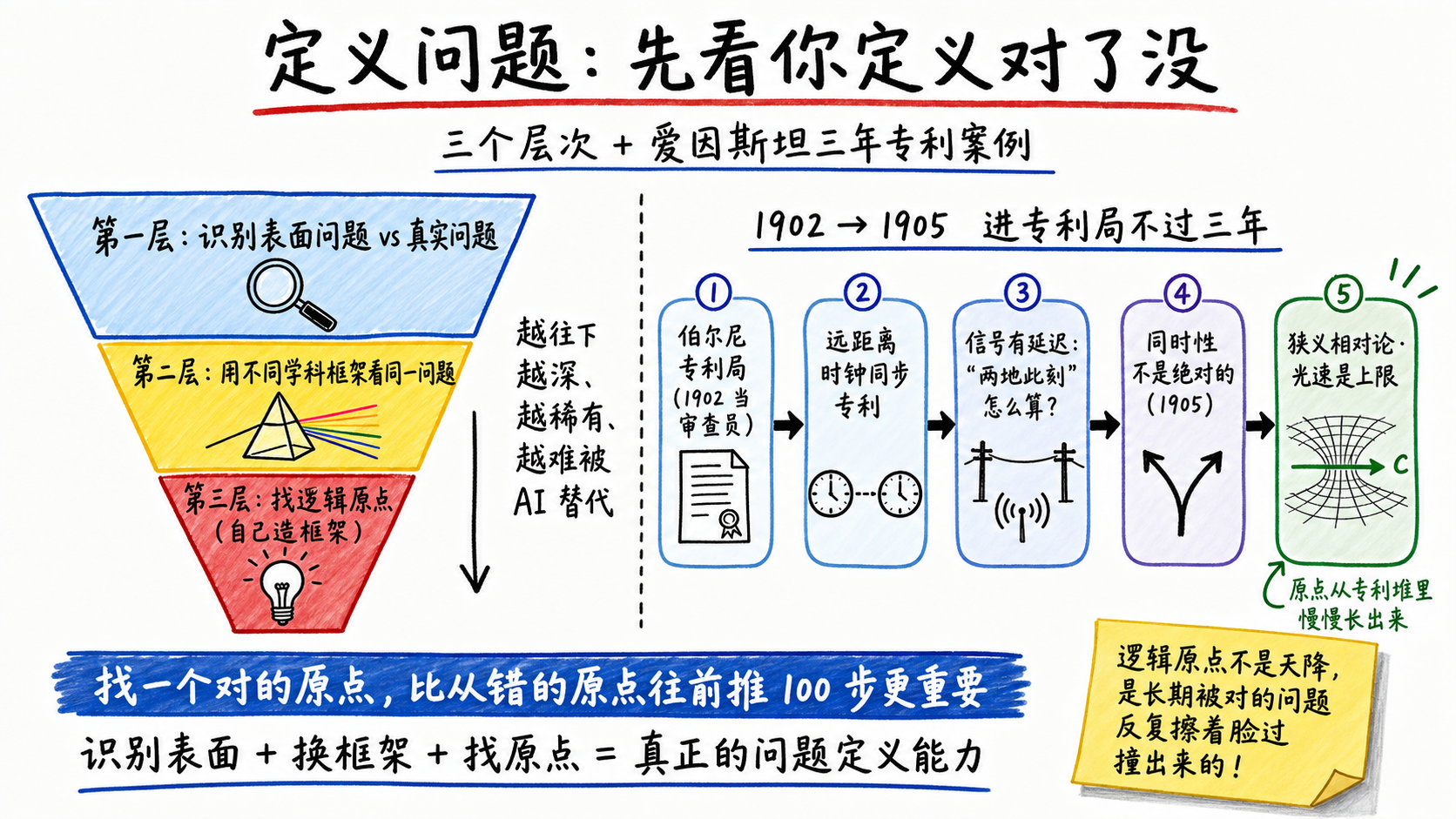
爱因斯坦那里有一句被反复引用的话:“如果给我一个小时解决一道关乎生死的问题,我会花55分钟想清楚这个问题到底是什么,剩下5分钟解题。” 找一个对的原点,比从错的原点往前推100步更重要。
但爱因斯坦能找到对的原点,不是靠灵感。他1902年进瑞士伯尔尼专利局当审查员。那个年代专利局里大量涌进来的是什么专利?用电信号同步远距离时钟的专利。当时铁路调度、海上经度测定、跨大西洋电报,全都依赖把相隔很远的两个钟对到一致。这是个实打实的工程难题:信号有传输延迟,怎么算"两地此刻"?
那几年,爱因斯坦每天看的就是工程师怎么解决"两个遥远的时钟如何定义同一个’此刻’"。他对"同时性"这件事的感觉,比任何同时代物理学家都深:别人是在课本上读这个问题,他是在审专利的过程中反复加深思考。
到1905年,他进专利局不过三年。狭义相对论里最反直觉的那个判断——“同时性不是绝对的,取决于参考系”——就是把他每天审的那个工程矛盾,往上升一维,变成了物理学原理。“光速是上限"这个原点,是从那几年的专利堆里慢慢长出来的,不是天上掉下来的。
科学史家Peter Galison在《Einstein’s Clocks, Poincaré’s Maps》里梳理过这条线:相对论的源头就埋在专利局那套同步时钟的工程实践里,而不是某个孤立天才的凭空灵感。用前面那张网的说法——爱因斯坦脑里正好把工程现场和物理直觉这两片本来不相干的区域连了起来,又在对的时间撞上了对的问题。普通物理学家也会演绎,但他们站的原点是别人给的;爱因斯坦自己找原点,因为他脑里那张网的形状跟别人不一样。
反过来更常见的情况,是有人手里捏着可以做大事的材料,却因为没有自己的原点,错过了20年。
清华大学心理与认知科学系主任刘嘉——早年在MIT读脑与认知科学博士,研究了几十年智能和意识,2025年写了本《通用人工智能》——拿自己当过反面例子:
“我为什么走了20年的弯路?……我没有信仰。Marvin Minsky说神经网络不靠谱,大师就是我的逻辑原点。”
刘嘉1994年就接触到人工神经网络。如果当时他能给自己定一个原点——比如"我相信人工神经网络能产生跟人一样的精神世界,所以我必须做这件事”——他会一头扎进去,可能就是Hinton那个位置。但他没有自己的原点。他的原点是"大师说"。所以他绕了20年。
清华教授承认这一点,需要勇气。但比承认更难的是另一件事——意识到自己的原点其实不是自己的。多数人这辈子都没意识到这一点。他们以为自己在思考、在做决策,其实是在执行别人给的原点:父母说要稳定就找稳定工作,社会说要房子就买房,行业说要跟风就追新概念。原点都是借来的。
把原点从一个问题放大到一整个人生——你为什么做这件事、什么是你愿意押上几十年去做的——是个更大的题目,值得单独一篇文章。这里停在工作的尺度:找一个属于自己的原点,知道自己为什么这么定义问题、为什么不接受别人给的定义——这一步AI替不了你。因为AI不知道你是谁、信什么、过去经历过什么。
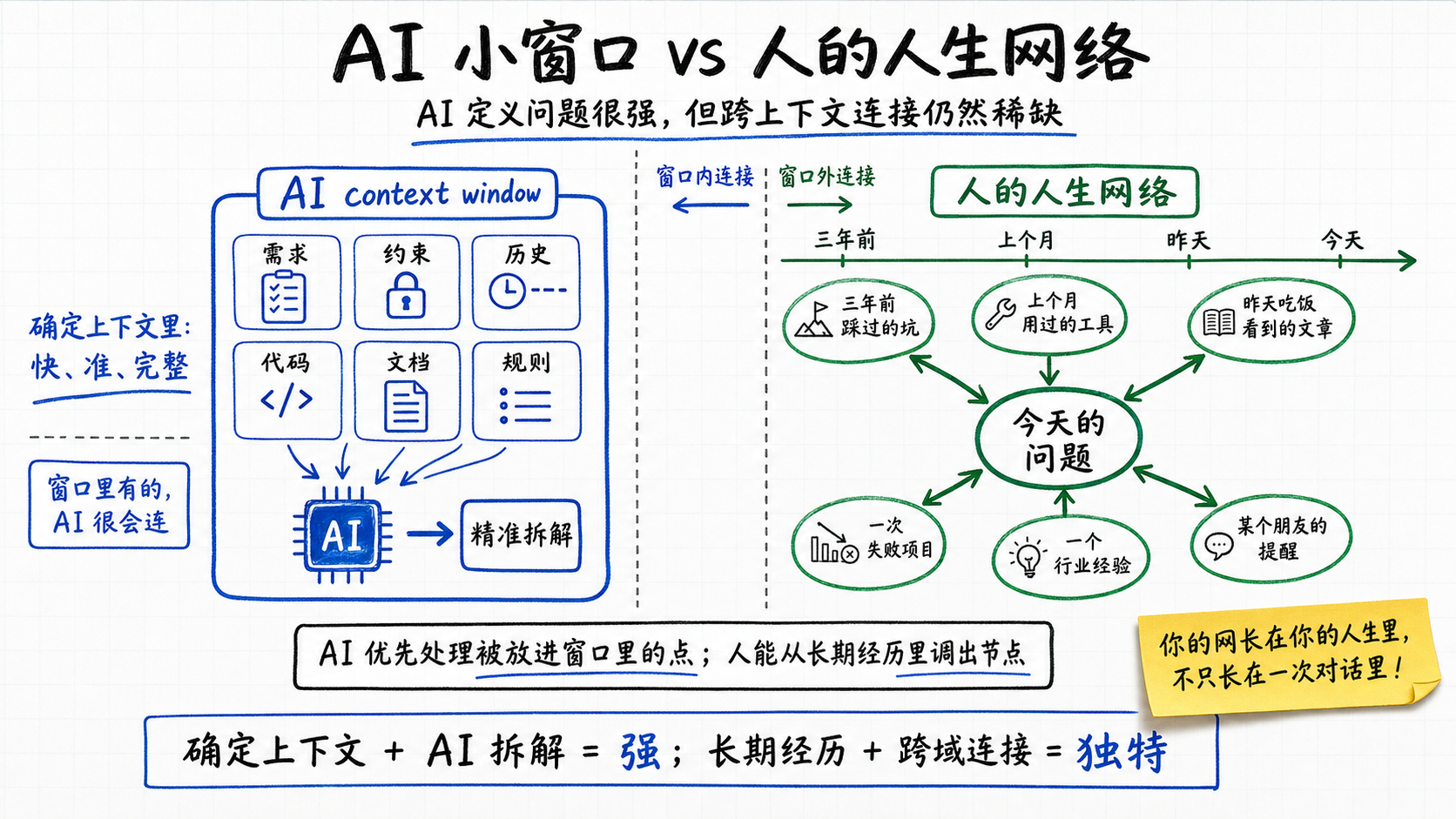
AI在定义问题上能做什么
这里要说清楚:AI其实很会定义问题。给它一段完整的需求、约束、历史,它在这个确定的上下文里拆解问题,比绝大多数人都快、都准,甚至能点出你自己没意识到的盲区。
它做不到的,是跨上下文的连接——只能在context window里连点,没法把你昨天吃饭看到的一篇文章、上个月用过的一个工具、三年前踩过的一个坑,跟眼前这个问题自然接起来。
举我自己一个例子。前段时间我测spec driven development,需要让coding agent在终端的多个子窗口里稳定交互,这事自动化起来并不容易。但念头一冒出来,几年前为完全不同的目的用过的PSmux(一个像tmux那样操作子窗口的工具)就自动浮上来了,问题当场解决。这条连接AI拿不到——它的context window里根本没有"我用过PSmux"这件事,那是我整个使用经历织出来的。
如果说,通用模型是大家共享的,那么我们每个人的人脑实际上是自己独有:主动判断"这个问题该升到哪一层",以及每升维一次就把那张网永久改写。AI能在给定的上下文里把问题拆得很漂亮,可爱因斯坦在专利局那几年织出的网,是长在窗口之外。多想、多接触、多做,主动去碰那些当下看不出用处的东西——窗口外的网,就是这么一点点长出来的。
五、元认知在决策里:识别哪个脑在做主
前面讲的元认知都发生在思考里——审视自己的判断、定义自己的问题、找自己的逻辑原点。这一章讲一个特殊场景:做选择。
选择跟思考不一样。思考可以慢,可以推翻自己,可以反复来。选择是一次性的:按下去就按下去了。买不买房、跳不跳槽、跟谁结婚、做不做这个生意,做完之后只有承担后果。
所以,决策时的元认知比平时金贵得多。平时多想几遍判断错了无所谓;决策时少想一步,一辈子的轨迹就偏了。
但绝大多数决策做得很糟。原因不在分析能力,在硬件:人脑本来就不适合做这种决策。
情绪总比理性先反应
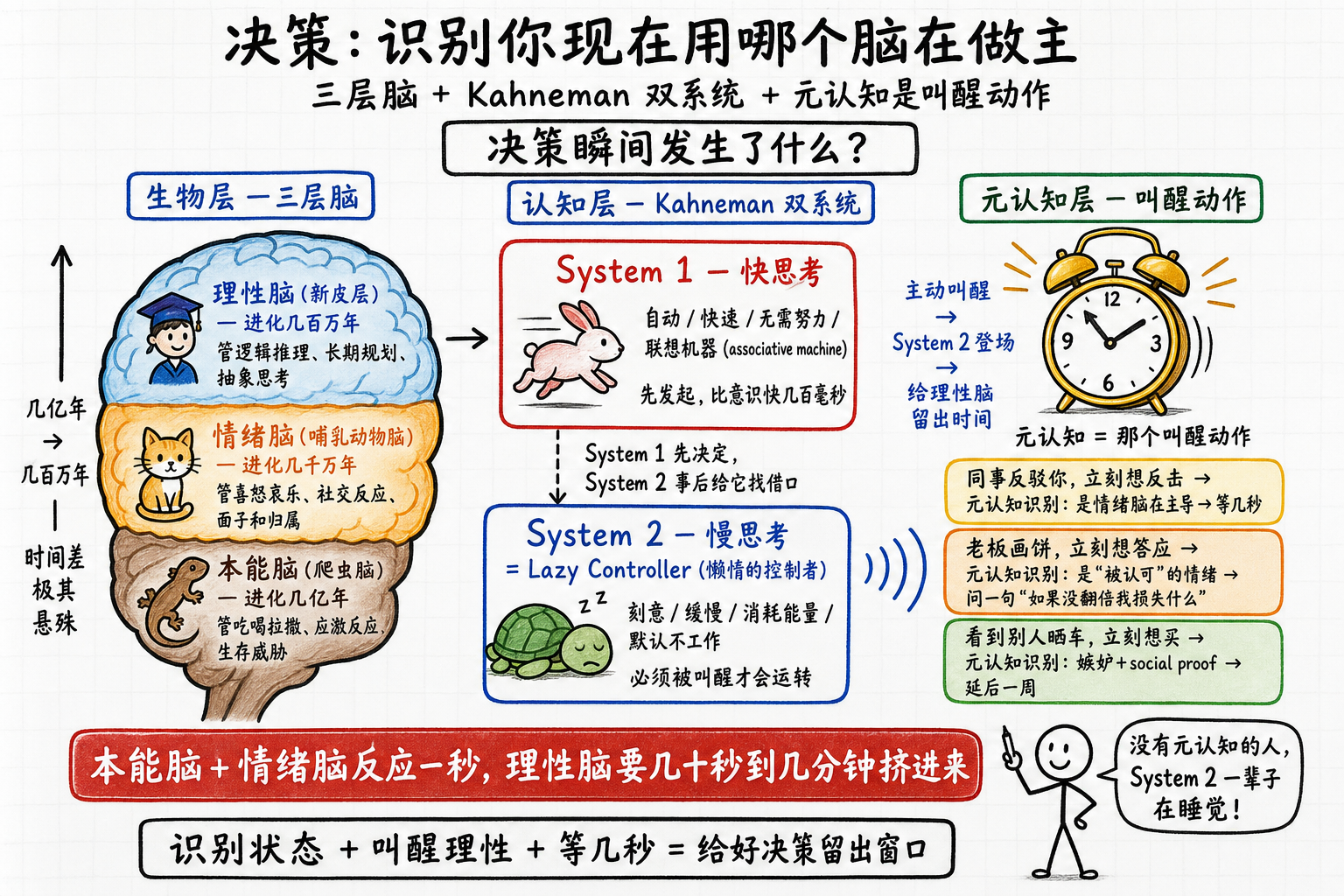
有个流传很广的"三层脑"说法,把大脑粗分成进化年代相差极远的三层:
- 本能脑(爬虫脑):进化了几亿年。管吃喝拉撒、应激反应、生存威胁。
- 情绪脑(哺乳动物脑):进化了几千万年。管喜怒哀乐、社交反应、面子和归属。
- 理性脑(新皮层):进化了几百万年。管逻辑推理、长期规划、抽象思考。
这个"一层层摞上去"的模型,现代神经科学其实早已修正——大脑并不是这么搭起来的,“你脑子里住着一只没进化过的蜥蜴"更是误传。但它当个直觉脚手架还算好使,因为它指向一个靠得住的事实:面对选择,情绪和本能总比理性先反应。理性要等它们表演完才登场,那时调子已经定了,它能做的只剩给情绪找理由。
Kahneman在《思考,快与慢》里把它分成两套系统:他把快思考叫System 1(系统一),慢思考叫System 2(系统二)。System 1是个"联想机器”(associative machine),把当下激活的概念瞬间串成一个连贯的故事;System 2多数时候只是事后给这个故事背书。所以行为经济学里有句话——人不是rational agent,是rationalizing agent:决定先由System 1拍板,System 2再回头给它找借口。
大多数人决策靠感觉。这感觉是本能脑+情绪脑+System 1组合后的输出,不是错觉。理性脑只是事后给这个输出贴一个看起来合理的标签。
元认知在决策中具体做什么
元认知不能让你不凭感觉——本能脑和情绪脑的反应速度比意识快几百毫秒,意识根本拦不住。
它能做的是另一件事:让你识别出自己现在被哪个脑主导。
几个具体场景:
- 同事在会上当众反驳你,你立刻很想反击。元认知在这一刻能识别出"我现在是情绪脑(面子受损)在主导",于是你能等几秒再说话——几秒之内情绪脑的爆发会衰减,理性脑能挤进来。
- 老板给你画饼说三年翻倍,你立刻想答应。元认知能识别出"我现在被’被认可’的情绪推着走",于是你能问一句"如果三年没翻倍我损失什么"。
- 看到朋友圈某人晒了50万一辆的新车,你立刻想"我下个月也要买"。元认知能识别出"我现在是情绪脑(嫉妒+social proof)在驱动",于是你能延后一周再想。
元认知在决策上的作用是给理性脑留出登场的时间。
Kahneman说得更直接——他把System 2称为Lazy Controller(懒惰的控制者)。System 2有能力反驳System 1,但默认不工作;必须被主动叫醒才会运转。元认知就是那个叫醒动作。一个没有元认知的人,他的System 2一辈子都在睡觉,所有决策都由System 1替他做,他自己以为是自己想清楚的。
这个代价比想象中大。本能脑+情绪脑反应一秒钟,理性脑挤进来要几十秒到几分钟。决策窗口就在那一秒之内关上了:脱口而出、当场答应、立刻购买、马上回复——然后理性脑用接下来的几个月时间为那一秒的决策找理由。
怎么训练在决策瞬间启动元认知
几个比较扎实的训练方法:
给重大决策强制设定冷却期。“24小时内不做任何超过X金额的决定”,“重大职业选择必须搁置一周再决定”。这是给理性脑买时间,不是优柔寡断。
预先准备暂停问句。在情绪起来的瞬间,问自己一句固定的话:“我现在是哪个脑在做主?“这一问就是元认知动作。一旦它启动了,情绪脑的主导地位就开始松动。
事后复盘自己的决策模式。回头看自己过去10个重大决策,多少是冲动做的、多少是冷静做的、各自结果如何。这种复盘会给你一份自己的决策偏差档案——下次再遇到类似场景,能更快识别自己处于什么状态。
AI时代的决策:System 2被接管,System 1靠你
AI在System 2这一侧已经追上甚至超过人——数学、编程、法律分析这些理性活,它都做得不错。给它干净的输入,它能输出比绝大多数人都更严谨的分析。
但这里有个隐藏的前提:给它干净的输入。你被情绪带着写的prompt,AI也只能基于这个prompt给你"合理化"的输出。AI不知道你的情绪状态,它默认你的输入就是你想问的问题。
举个例子。你刚刷到一篇博客,把某个新框架吹得天花乱坠,一时动了迁移的念头,打开AI:“帮我评估一下把现在的项目迁移到X。” AI会很认真地给你列一份迁移方案——技术选型、风险点、分阶段计划,看起来非常专业。但它给你的整个分析,地基就是歪的——因为你该问的是"我现在到底是被新鲜感冲昏了,还是真有非迁不可的理由”,而不是"怎么迁移到X”。
Kahneman把这种"用一个问题替换另一个问题"的动作叫substitution(替代)——人面对难问题时,System 1会偷偷换成易问题来回答(“这位候选人有多胜任"被换成"我有多喜欢他”)。AI时代有个新变种:你被冲动带着,把当下真正的问题(“我是不是在为了用新技术而用新技术”)替换成一个AI能漂亮处理的假问题(“迁移到X的方案是什么”)。AI严肃地给你假问题的答案,你以为问题解决了。
AI在System 2上替你工作得越好,你就越容易跳过自己的System 1管理直接让AI工作。结果是——用最严谨的工具,做最草率的决策。
所以AI时代决定决策质量的第一件事,是给AI提交问题之前,先把自己的System 1调到中立状态。
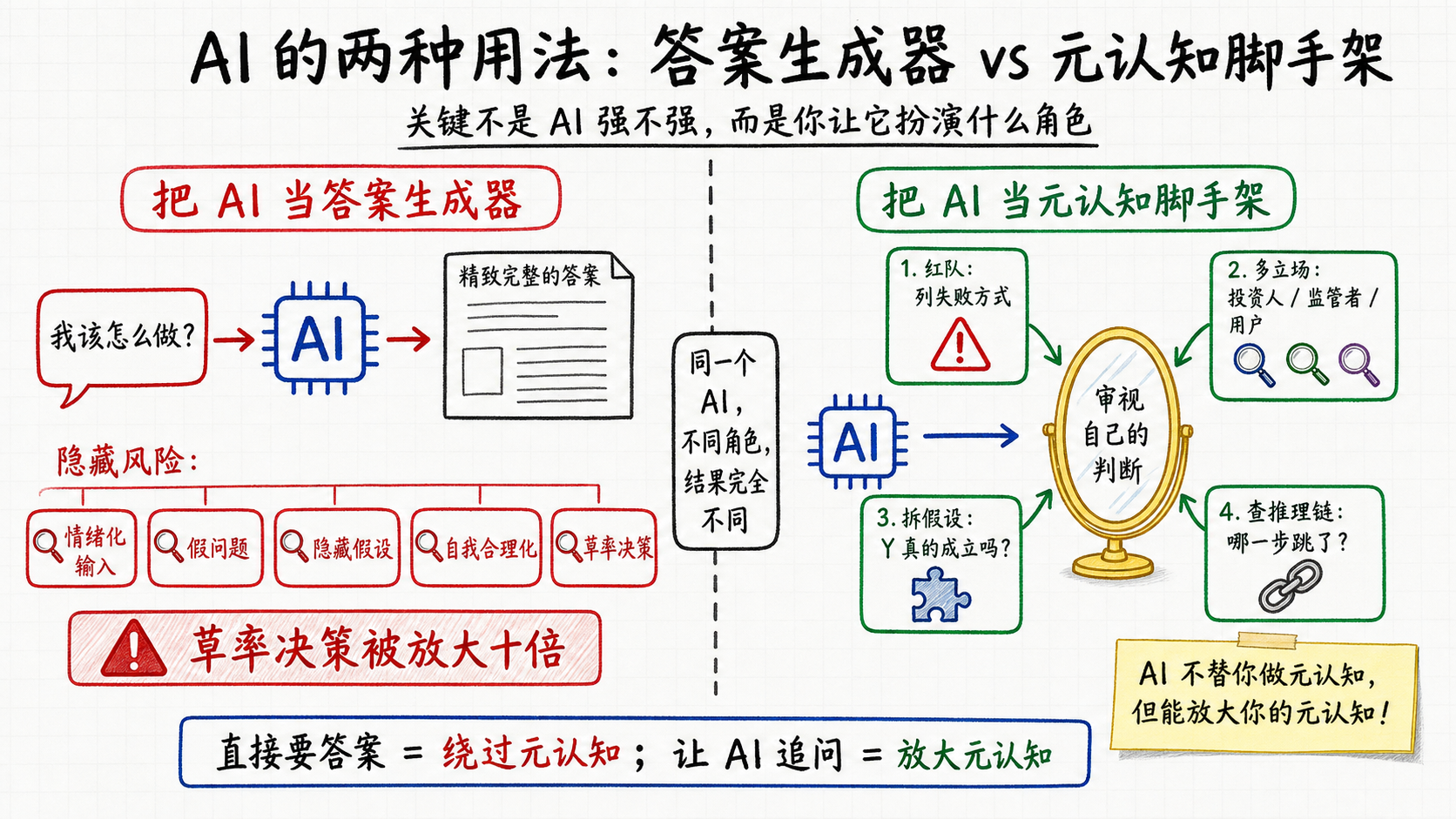
把AI从答案生成器换成元认知脚手架
但这只是一半。另一半是反过来——主动用AI来强化你自己的元认知。
元认知强的人有一个反直觉的特征:主动找自己的错。主动测试自己理解的边界,主动暴露自己的盲区,主动给自己最确信的判断找反例。元认知弱的人刚好相反:回避犯错,只做擅长的事,只接受符合自己观点的信息,于是认知原地踏步。
分水岭就压在一个问题上:如果我错了,我会怎么知道?
第二章说过,承认自己错了在生理上接近疼痛;靠别人来问,敢直接刺你的人本来就少,刺得起的关系更少。所以多数人一辈子都在问"我怎么证明我是对的",从不问反面那一句。
AI把这个成本打到了地板上。它随叫随到,不嫌烦,刺你不用顾及关系;被它驳倒也不丢人——没有观众。第二章那面递到门口的镜子,递的就是这件事:让"如果我错了,我会怎么知道"从一件高成本的事,变成一句随手就能问出口的话。
具体怎么问,是同一个问题的四个变体:
- 问方案:“不要评价优点,列出这个方案会烂尾的十种方式。“人对自己提的东西有endowment effect,自己的方案怎么看怎么顺眼;AI没有这层滤镜。
- 问立场:“换成挑剔的投资人、严格的监管者、极度怀疑的用户,你们各会问我哪五个最尖锐的问题?“你自己想问题,默认只有一个立场;多请几个立场进来,等于几张网交叉照。
- 问前提:“我打算X,因为Y——Y本身站得住吗?我还默认了哪些没说出口的前提?“AI极擅长挖隐藏假设,它没有"这件事就该如此"的预设。
- 问推理:“这是我从前提到结论的完整推理,指出哪一步跳了、哪一步在循环论证。“人审自己的推理链,最容易在自己最得意的那一步快进;它不会。
判断标准也要跟着换:从"AI觉得我的方案不错”,换成"AI使劲挑也挑不出致命伤”。前者没有信息量——夸你是它的默认行为;后者才算过了一关。被它驳得难受也不用急着泄气:用第一章的说法,那正是你网里某片稀疏的区域被照亮的时刻。
这四个变体有一个共同点:你交给AI审的对象,从外部世界换成了你自己的判断过程。它仍然进不到你的网络里——它不知道你为什么会这么想——但它能把你想的过程摊开在桌面上,让你自己看见。
所以前面"AI在System 2上接管"那句要补一个限定:AI接管的是对外的System 2(分析问题、生成方案、严谨推理);对内的System 2,也就是元认知(审视自己怎么想、为什么这么想),得你亲自上手——AI能当的,是手边那副脚手架。
六、改变为什么这么难
这里得说一句诚实的提醒——看完这篇文章,你大概率不会变。
至少不会立刻变。这不怪你,是改变本身太难。
刘嘉自己也承认:到现在他都不敢说自己有AI原生的思维方式,每天还在琢磨怎么和AI对话、怎么共生——改是一件很痛苦的事,人太容易被原有习惯带走。一个研究脑科学几十年的清华教授都这么说。
难有硬件原因。人的认知结构到25岁前后趋于稳定——前额叶皮层发育成熟,你看问题的默认框架、情绪反应模式、价值排序,每一样都对应一片成型的神经回路。神经可塑性终身都在,改是能改的,但以年计,不以周计。
元认知的改变还要再难一层:它是自指的。要改自己的元认知,得先意识到自己元认知不行;而元认知不行的人恰恰最难意识到这一点——Dunning-Kruger效应说的就是这个。靠自己想是想不破的:你的思维工具本身,就是要被改造的对象。所以得借外力。
什么情况下人会真的改变
观察下来,只有四种场景——
Hurt enough(痛够了)。失业、离婚、生病、破产。痛到旧的思维模式hold不住,被迫重建。
See enough(见够了)。出国、跨行业、跟强一个数量级的人共事。差距大到旧框架自动崩塌。
Know enough(懂够了)。一千本书、一万小时。量变到了,质变才发生。
Receive enough(被支持够了)。被好的环境长期滋养,旧的反应模式被慢慢替换。
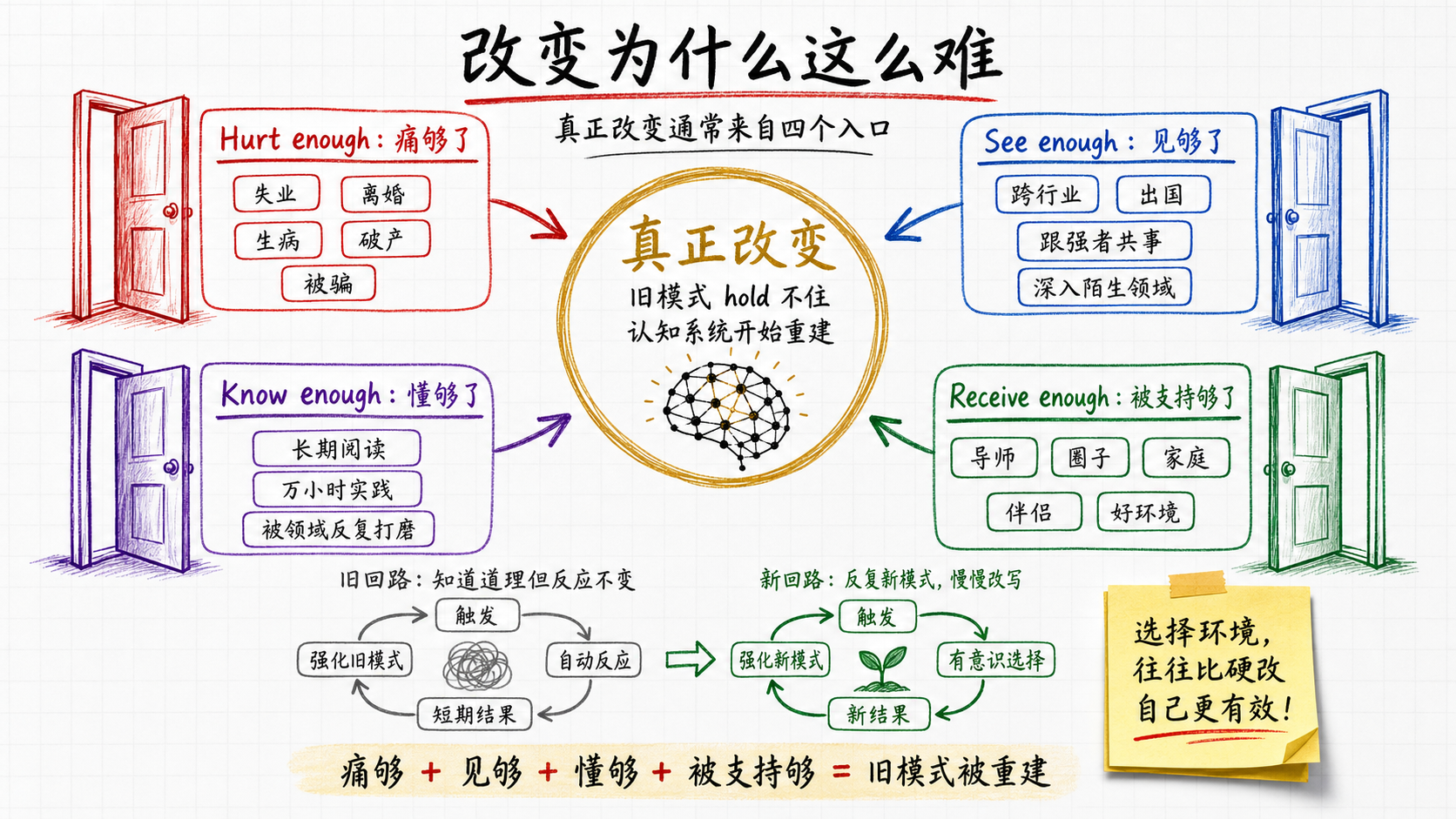
前三个入口等不来也求不来:痛、见、懂,都要靠机缘。只有第四个,环境,能主动选。
你很难改变自己,但你可以选环境,让环境改你。 读博的人都懂:同一篇论文,在头部团队里有导师带、有更强的同侪推着走,和一个人闷头摸索,难度差几个量级。不只读博——跟谁共事、待在哪个行业、每天被什么信息流喂养,都是同一回事;最被低估的是跟谁结婚,伴侣的元认知水平几乎框定你后半生的认知环境。
烧火棍与金箍棒
到了AI时代,选环境多出一个新维度。
AI研究员田渊栋在2025年的年终总结里给过一个比喻:人类社会的费米能级。把一个人加上他能调用的AI看成一个整体,这些整体的能力分布就像材料里的电子能级——低于某条水准线的遍地都是,高于的指数级稀少。这条线就是AI洪水的水位:人加AI强过AI本身,价值才开始计数;低于水位的职业,可能一夜之间被端掉。
决定你在水位哪一侧的,是认知。流行的说法是你赚不到认知范围以外的钱;同样,你只能把AI用到你认知范围以内的水平。工具一样,天花板被各自的认知锁死。
今年跟朋友交流,这一点看得很清楚:同一个AI,一部分人手里是烧火棍,一部分人手里是金箍棒。金箍棒那批人有几个共同点:好奇心重——新模型新工具一出来就上手,自己去摸这个外星工具的边界在哪;自驱力强——没人布置任务也在折腾;不怕犯错——试砸了换条路再试,跟第五章主动暴露自己的错是同一种性格。跨界是这些特质里最显眼的外化:能把八竿子打不着的东西串起来,所以今年那么多搞计算机的跑去看脑科学、认知科学、心理学。先吃透自己的领域,再去别处织节点——哪天某个灵感把两片不相干的区域串起来,那就是护城河。第一章那张网,织到这个密度就是护城河。
所以今天选环境,划分的单位变了。以前是选公司、选部门、选导师;现在人按用AI的深度重新分层——深度用AI的人和不怎么用的人,做事方式已经是两拨人,而且前一拨很少公开交流,连接多半发生在线下。选环境就是主动去找他们:看他们怎么工作、怎么拆问题、怎么把推理和审视丢给AI去跑——在他们那里,AI是凭空多出来的一队聪明助手。这远比劝不想用的人有用——配置甩到脸上都不会装的,劝不动;时间该花在找同类上。
环境的另一半,是你手里的AI本身。先是用什么:永远跟最前沿的模型和工具——Claude Fable 5这种新模型一发布就深度试用,而不是拿小参数的蒸馏版凑合干活。水位线一直在涨,工具停在哪一代,你对AI能力边界的判断就停在哪一代——烧火棍多半就是这么用出来的。再是怎么用:让它顺着你——你说什么它都先夸两句再附和——它就是一个永远不会刺你的环境;让它默认当红队——方案先按第五章那套做一轮对抗式评审——它就是随叫随到、敢直接刺你的声音。没有导师和同侪的人,这一半反而是最便宜的起步。
如果你想升级元认知,最实在的路径是先升级环境:一半是你身边的人,一半是你手里的AI。
结尾
AI时代的能力定价表正在重写,被排到最前面的,是你审视自己的能力。
学习里它叫升维,解决问题里它叫定义问题,决策里它叫管理自己,应对改变里它叫选择环境。说的都是同一种能力:AI替不了你,但只要你肯做,它能帮你把每一样都做得更深。
最便宜的几样——执行、记忆、生成、严谨推理——AI全包了。
最贵的几样——知道自己不知道什么;知道自己为什么相信现在所信的;知道自己该往哪儿去——AI不替你做。至少在当前这种没有内生需求、只在给定上下文里工作的架构里,看不到它替你做的可能。
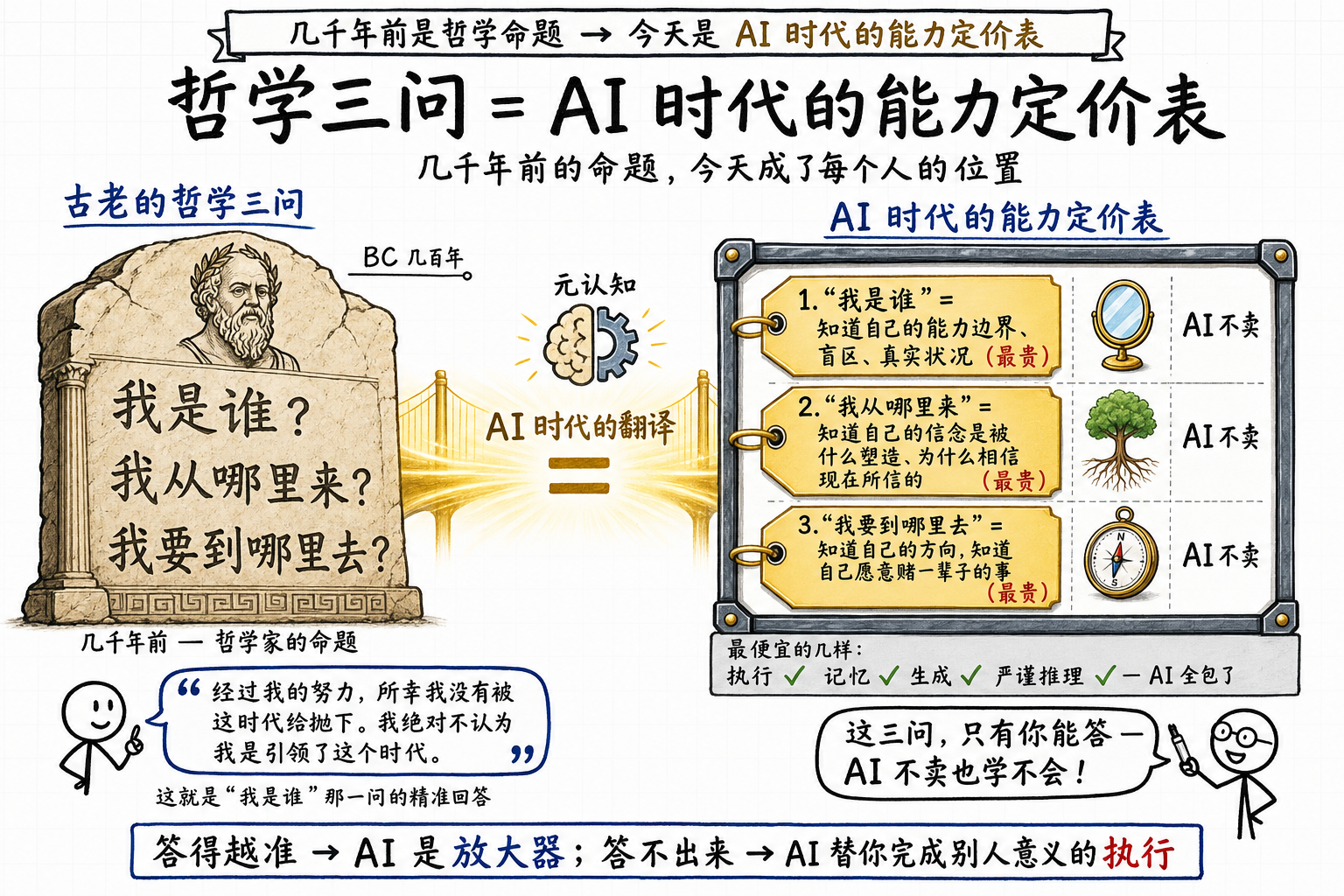
仔细一看,这三件事就是哲学里那个最古老的三问——
我是谁。我从哪里来。我要到哪里去。
几千年前提出来的时候,是哲学家的命题。今天,它们成了AI时代每个人的能力定价表:
- 我是谁 = 知道自己的能力边界、盲区、真实状况
- 我从哪里来 = 知道自己的信念是被什么塑造的、为什么相信现在所信的
- 我要到哪里去 = 知道自己的方向,知道自己愿意长期做下去的事
这三问你答得越准,AI越成为你的放大器;你答不出来,AI替你做的所有事都跟你没关系:技术上是你完成的,说到底是别人意义的执行。
刘嘉在最近的一次访谈中说——
“经过我的努力,所幸我没有被这时代给抛下。我绝对不认为我是引领了这个时代。”
一个清华教授的最高自评是没被抛下。这句话本身就是高水平元认知——他准确知道自己站在哪,既不夸大也不矮化。这就是"我是谁"那一问的精准回答。
AI的水位线还会一直涨,执行、记忆、生成、推理,会一样一样沉到水面之下。往远处看,这是人类第一次卸下这副担子。几千年里,问自己是谁是极少数人的奢侈,其余的人被生计填满,一辈子顾不上问。AI把能做的事一样样接走,等于把这份奢侈第一次发到每个人手上:哲学家的三问,变成了人人都问得起的问题。
最后分享一段话,算是对自己的提醒:我的肉身只需要很少的粮食,我的精神需要山川河流和自由。我怎能一生忙碌,只为喂养一副终将衰老的躯体,而不珍惜和我相伴至死的灵魂?
这个时代,信息爆炸,知识过载,每个人都很忙。但忙碌之余,留一点时间给认知的成长。